From data to data model

Do you remember this fiction movie “Next” with Nicolas Cage where a man was able to predict the events two minutes ahead in the next future thanks to a gift that allow him to “see” it ? With his ability, he was able to help the FBI solve a mastermind terrorist conspiracy by trying over and over actions until he was able to find the right ones
The good news is that we are close to be in that world, the bad news is that this miraculous help is not smelling the aftershave and is probably standing in a closed room, smelling heat and dust in the suburb of Beauharnois.
Why ? Because this is a called a data simulation model and such a solution benefits from scalable environment of the public cloud, as that one of the biggest data center in the world located in Beauharnois in Canada operated by the french operator OVH.
A data simulation model can be associated with a lot of buzz words like AI (artificial intelligence), Big data, neuronal network … because the core principle of a data simulation model is to be able to create new data from existing data, based on an algorithm that have been either created by a human (standard programming) or trained from a set of existing data (like a neuronal network).
As shared in previous posts like From raw to optimized cost of a digital solution, the data simulation model is the solution to move from the information of the past (historical data) to the future (simulation data).
In this post, I would like to dive into this concept with you, and for that, let’s start with a funny reference
If you are a sci-fi and humor reader, you probably knows the book “The Hitchhiker’s Guide to the Galaxy” from Douglas Adams. As one of the many humoristic ideas in this book, the author presents the earth as a vast simulation computer built by an extraterrestrial intelligence to process the “Answer to the Ultimate Question of Life, The Universe, and Everything”. This vast simulation was expected to expand the result of the previous computer version that was 42.
Aside from the crazy British humor that come with it in the books, from a pure data science point of view, the idea of the author is pertinent because the reality is the perfect data simulation model that can always predicts what will happen.
A data simulation model is a model that will generate, with some errors, a simulation of the evolution of the current data. Those simulation data will allow to create an approximate version of the future. The accuracy of the model is measured by the difference between the simulation data and the observed data in the following time period.
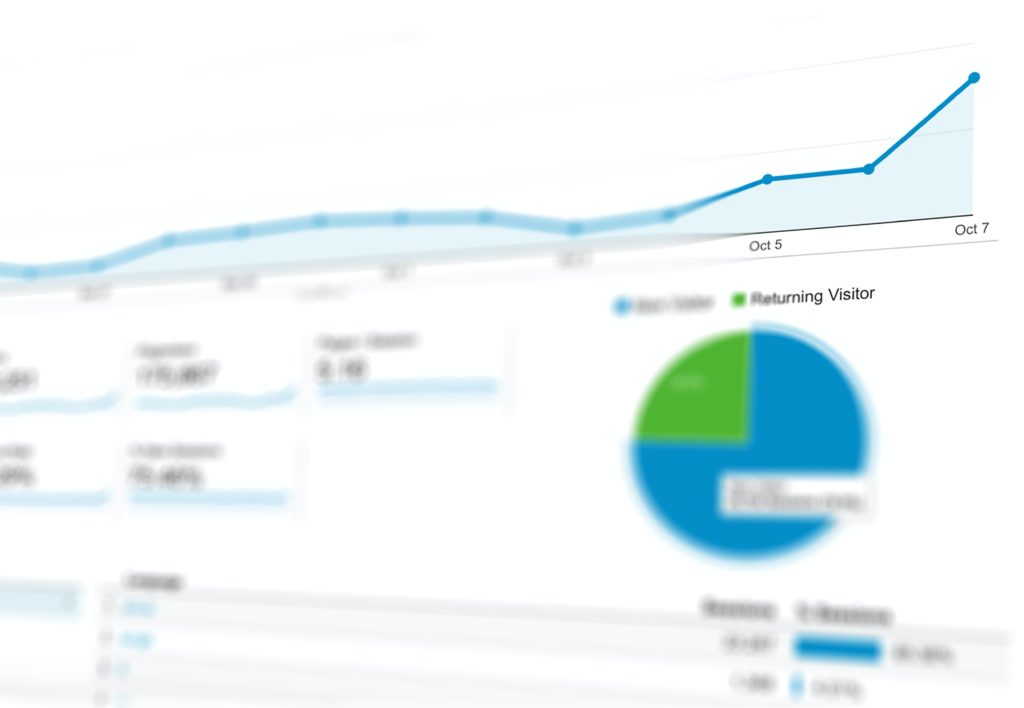
We are all familiar with one of the most simple version of a simulation model that is a trend line on a chart that present the projection evolution of sales, customer visit or consumption of goods. Over time, with development of discipline like data science, we have created more and more complex data simulation model.
Data science is the field of study that combines domain expertise, programming skills, and knowledge of mathematics and statistics to extract meaningful insights from data.
https://www.datarobot.com/wiki/data-science/
If, we look at a model from a scientific information theory (initiated by Claude Shannon in 1948), a data simulation model is a compression function that allows to create the data after an observation point with less input information than the information contained in the entire reality.
A data simulation model have the following advantages
- The information needed to store the data model are smaller than the data used to create it and the data that it can creates
- A simulation model produce a synthetic view that is easier to understand that the full data set
- A simulation model can be executed from any data point (moment in time)
- A simulation model can be executed multiple times on a single data point by varying parameters to compute a different view of the future
- A simulation model can be improved over time by comparing the prediction and the reality
To fully understand those advantages, let’s look at them one by one.
Data compression
We are so used to data compression that we often do no realized that it has been applied to many aspects of our life.
Data compression is a technique that allows to reduce the data by creating a representation of it that have a similar level of information.
For example : 55555555 can be represent by 8×5, 8 times the number 5.
There is two kind of data compression
- Data compression that will allow to recreate the original information (Lossless)
- Data compression that will allow to recreate an information close to the original but not identical (Lossy)
My previous example was a lossless compression, ZIP compression is another. On the other side, lossy compression is used for example by Google Photo to reduce your pictures size before storing them on the cloud.
The main goal of a lossy compression is to convert the data to a pair of seed/function. The seed is provided to the function to recreate the data set with an error level that is acceptable.
But how do we create this conversion ? The core principle comes from a mathematical theory popularized by Isaac Newton that, in a simple view, define that any signal can be approximated by a sum of basic harmonics ( a signal with a frequency shape ).
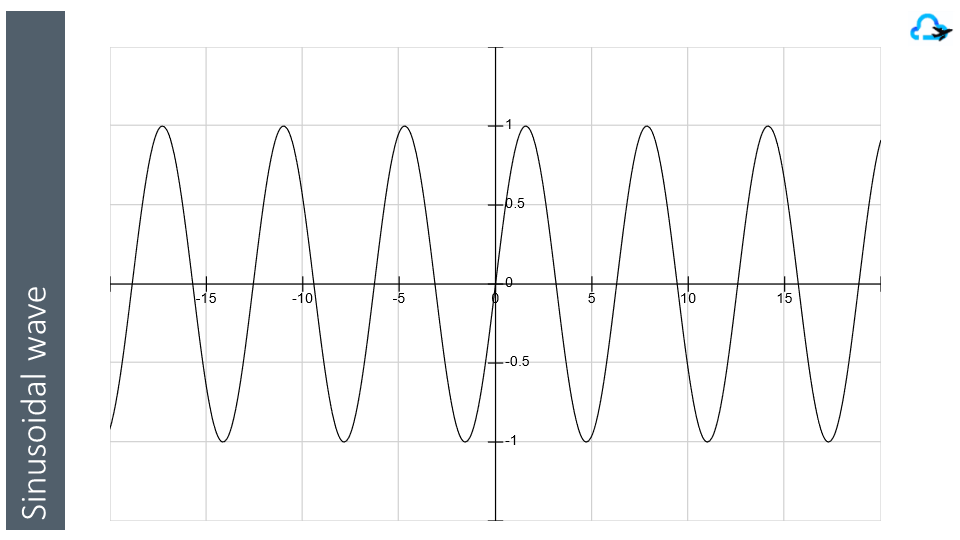
The principle has been the source of many researches aiming to provide methods to do such analysis like the popular Fourier-based frequency decomposition.
The low frequency harmonic capture the global evolution of the information, the high frequency harmonic capture the details.
So the main information can be approximated by keeping a subsets of the harmonics and loosing some details
The information that we capture from the world is simplified as signals in one or several dimensions and approximated by those techniques.
Let’s look at examples :
Music is simplified as a one dimension signal. Frequency compression method like MP3 allows to reproduce the signal with accuracy. Noise cancelling creates low frequency harmonics in the opposite phase of the original ones to create a flat signal that we do not hear
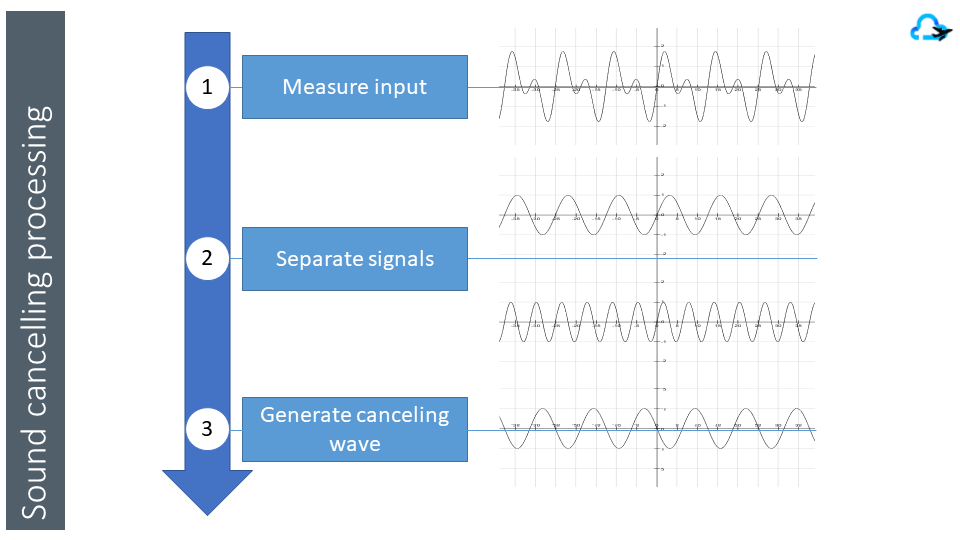
Images are captured as a two dimension signal digitized as squares (pixels) with a dominant color. Images can be stored with lossless compression like PNG, but lossy compression like JPG (using frequency compression method) allows to reproduce the signal by approximating the color of each pixel with a smaller set of information
Finally, your position is captured by your phone as a 3 dimension signal thanks to the global positioning system (GPS) and the environment is simplified as a 3 dimension digital terrain model (DTM). From there, your itinerary is approximated by Google by a set of lines in 3D and, with a simplified model of parameters (like your speed and the fluidity of the traffic) Google Map can predicts your arrival time.
As we see in all those examples, data lossy compression allows to reduce the reality to a smaller data set that can be used for processing. From there, a data simulation model will generate future data that will drive decisions.
Synthetic view
A synthetic view is a view of the reality that allows to understand a main dimension of a situation and trigger reaction more quickly. For example, Google Map highlights the traffic flow in front of you with a color (green/orange/red) so that you can anticipate traffic deceleration.
The reason of using a synthetic view for processing is due to the fact that, the data that you have about the situation, have several drawbacks :
- Noise.
Differences between the real data and the data that you have captured due to the sensor or the capture method - Errors
Information that are inaccurate due to the capture or the transformation before processing - Redundancy
Information that is present more than once. Shannon explained that redundancy is useful in nature and human created data to allow error correction (for example in language). - Volume
It is often difficult to get an understanding of a situation with too much data. As a note, on that matter, Big Data is just a qualification that your simplified data set is still big compared to your processing and storage capabilities
The simulation model will use a synthetic view to do a faster processing and deliver its answer. A good example of the benefit of the synthetic view is the fall detection services that are developed in the domain of house surveillance.
The model create a simplified representation of the person (also called Voronoi skeleton) by an image processing type called morpho-mathematics. From there, the skeleton is even more simplified into a set of articulated line (a kind of puppet) so that motion and falls can be detected more simply
The choice of the information used in the simulation model is important.
Travel in time
Time travel has always been a human dream. The goal is to be able to observe or change the past.
As a simulation model is able to compute the future data from any point in time. This ability can be used for many purposes. For example, if a data point is in the past, the model can assess its accuracy by comparing generated data and real data. If the model is created to test an hypothesis, it can also evaluate impacts by comparing the difference between the observed data and the simulated one.
However, as a data model use a synthetic view, the accuracy of the model is often valid only for a specific period in time (its validity domain). The reason is that the data model is build on the assumption that the evolution of the data is consistent with previous experiences.
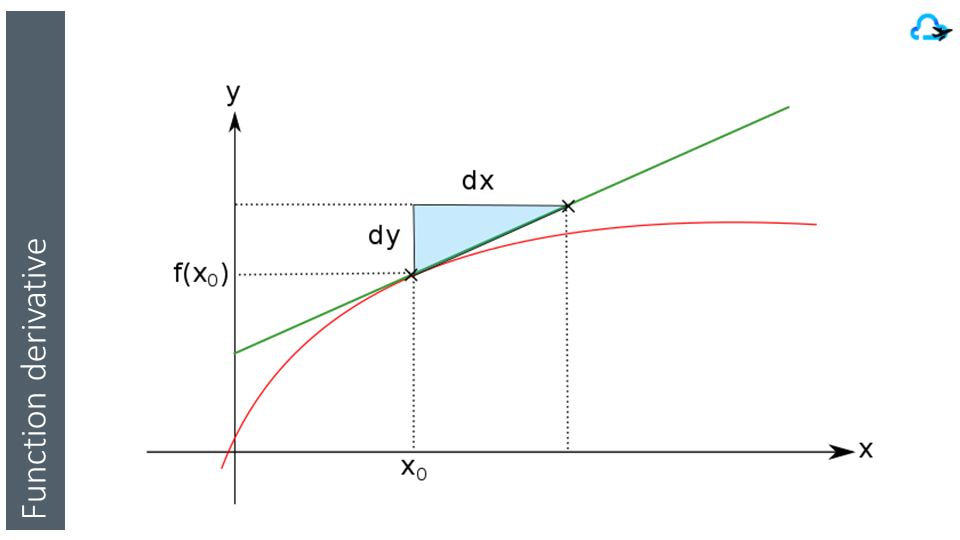
If the event that occurs has a huge impact on the behavior but is not part of the synthetic parameters of the model, the prediction is expected to be inaccurate
For example, a crisis like the COVID was not part of many data models and creates then the need to update them.
A disrupting event can have two effects :
- Change the level of the input or the trend of its evolution
For example, a storage silo that is contaminated and need to be trashed or a catalyst that speed up a chemical transformation - Change the behavior itself
For example, people that purchase now more goods on a tablet than on a computer a few years ago
Multiple futures
The data simulation model is a tool that allows to answer questions that starts with “What If … ?”. The goal is to be able to provide a situation as an input and to generate expected output.
For example, if my loan is $10 000 and my compound rate is 5%, what will be my monthly payment and the evolution of my debt overtime ?
In this example, I can evaluated different amounts of money and different rate and generate different future simulation.
When the model is more complex, the input parameters can be more numerous. It can incorporate information that will specialize the model (like the consumer profile) or influence its behavior (like the time allowed to make a choice)
Processing multiple scenarios gives important insight for the decision.
For example, a business simulation model will often test the best scenario, the worst and the most plausible.
If you are a game player, you fully understand the value to test over and over a situation until you find the right sequence or the right trigger to unlock the situation.
The data simulation model gives you this flexibility by providing you insights of the output of each simulation.
As your maturity on data simulation model evolves, your value will shift from predicting the output to define the appropriate decision to optimize the output.
For example, from “predicting the next oil change of your car” to “defining the best driving habits to have the longest life of your oil”.
Compare and improve
For each of those subjects mentioned above, the good news is that data simulation model can be improved over-time in several ways.
The most simple one is to correct the behavior and reuse the same data set to test it. With trained data model, this loop can even be executed automatically as the model “learns from its mistake””
In neuronal network, this is called back propagation
Back–propagation is just a way of propagating the total loss back into the neural network to know how much of the loss every node is responsible for, and subsequently updating the weights in such a way that minimizes the loss by giving the nodes with higher error rates lower weights and vice versa.
https://towardsdatascience.com/how-does-back-propagation-in-artificial-neural-networks-work-c7cad873ea7
The second axis is to expand the model. If an input parameter of the model evolves over time (like for example the level of passengers travelling daily by aircraft), the evolution of this parameter can be incorporated in the next version of the model.
The third axis is to separate the simulation model into smaller self-contained model. This separation improve the scalability of the model, its capability to evolve and its observability.
For example, we can simulate the traffic of a city by combining together 3 smaller models : a human simulation model, a car simulation model and a bus simulation model.
This separation have the same approach than the fourth industrial revolution that separate monoliths products into smaller smart products that interact together. And, as you probably understand already, your data model separation allows to create many simulation scenarios that integrate real models in the loop (progressive test integration plan).
However, the separation of the simulation model into sub-models needs to be executed with several consideration in mind
- Separating context can influence the data correlation of the simulation
For example, if the communication between two players in a game is limited, their behavior will be affected - The way to separate is an opinionated choice on the simulation
For example, defining a motorcycle and a car model indicate that you expect two different kind of behaviors - The orchestration of the sub-models is a sub-model by itself
For example, in the city simulation, how many cars does a family own ?
There is no right or wrong answers in general. You will have to decide how to answer to those considerations based on the goal of your simulation

The evolution towards simulation models
In a previous post The 3 models of the digital transformation, I highlighted the fact that a data (or the information contained in the data) is versatile and can create various values with its transformation.
The same statement applies to data simulation model, as the description of the data model itself is data as highlighted in a post of Teradata.
Why You Need to Treat Models Like Data
https://www.teradata.com/Blogs/Why-you-need-to-treat-models-like-data
But the fundamental difference is in the fact that a data simulation model is able to create data that are similar to the original data.
Due to this, a model can replace the data themselves if executed in a compatible situation. This ability creates many new opportunities
- Smaller form factor
As the simulation model is smaller than the original data, it can fit more easily in equipment that have limited storage capacity - Decorrelation between data and behavior
The behavior created can be used with other data than the original data - Scalability
As long as the number of instances of the data model does not influence the behavior, the simulation of 10 or 10000 consumers for example is only a matter of scaling the simulation infrastructure - Independence of evolution
Each sub-model can evolve independently from each other (pace, behavior, accuracy …) - Privacy protection
As the model does not have the original data, the sensible data present in the original data are not there also
On that last statement, I need however to give an important note. If a simulation model has been trained with personal data, a part of those personal data still reside in the model. To illustrate this, a study has shown that a computer knows more about a person’s personality than their friends or flatmates from an analysis of 70 “likes”, and more than their family from 150 likes. From 300 likes, it can outperform one’s spouse.
To conclude this post, let’s look at concrete examples of products that already leverage each of those opportunities.
- Form factor
A smart home thermostat host a simulation model that drive the decision on the profile used to heat or cool the house. The model is optimized for the form factor of the thermostat and its restriction in terms of power consumption. - Decorrelation
The same home thermostat send data on the cloud to allow a new model to be trained and will download the new version later. Data correlation between several thermostats allows better predictions. - Scalability
Almost all games include non-player characters (NPC) that are animated by the computer. The scenario will scale new characters on demand. - Independence of evolution
In the design phase of an aircraft, each component of the aircraft is simulated in sync to observe the evolution of the system. Each component model is updated overtime as its equipment specification is refined and implemented - Privacy protection
Evolution of the spread of a virus can be simulated without keeping the data of the original patients that have been observed while they were treated for it
Overall, with the digitalization of the behaviors that data simulation offers, we are at the verge of providing important new values by improving decisions with future forecast and behavior understanding.